
What is it and Why it is important?
In simplest terms, “markerless tracking” is the ability to track the movement of human beings without instrumentation attached to the body. Most traditional tracking technologies involve attaching reflective markers or 6DOF sensors (Inertial Measurement Units or electro magnetic sensors) to body segments to determine the position and orientation of the segment. Markerless tracking would extract that information with less invasive methods using digital video.
Instrumenting subjects is a problem on many levels. Elite athletes are particularly sensitive to unusual stuff hanging on their bodies and researchers have more generally worried that instrumentation affects the subject’s natural movement of the activity they are studying. The process of instrumenting subjects is time consuming. And instrumentation generally confines a study to laboratory settings. Accurate, realtime, markerless tracking is the holy grail of motion capture!

A Little History
We have witnessed remarkable transformation in the tracking of human motion during our 30 years in the business. Manual digitization of 2D video files first done in the 1800’s was still prevalent in the 1960’s.

It wasn’t until the 1980’s that Oxford Metrics and what would become Vicon could track reflective markers attached to the body and report 3D positions. While a significant advance, low measurement rates, manual identification of markers and post processing still left a lot to be desired. By the early 1990’s, Polhemus and Ascension Technology had introduced 6DOF electromagnetic sensors that could report position and orientation in real time at rates in excess of 100hz. Beginning in 2000, Xsens popularized the use of IMUs in motion tracking. From there we have seen remarkable advances in performance for most all the technologies. Smaller, faster, easier to use; camera companies today offer high speed, real time streaming of not only marker trajectories but also processed human motion inferred from those markers. Despite the advances, we are still faced with instrumenting subjects and limitations on the conditions under which data is collected.
Enter markerless motion tracking. Our first involvement with markerless tracking dates to 2009 and our support for a fledgling company pursuing tracking from digital cameras. Organic Motion, founded in 2002 and now inactive, offered a system that extracted subject positions and orientations from digital video collected from 8 cameras. It had the advantage of no subject instrumentation. Step into the space, take a neutral pose and then record or view subject motion in real time. However, measurement rates were limited to 60hz and collection required special backgrounds that limited its use to laboratory settings.
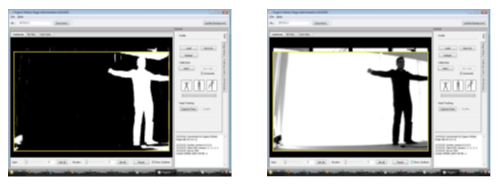
Many of our clients found the technology very useful. Autistic children that would not submit to instrumentation loved making Donald Duck move on the screen in time to their movements. Stroke patients who could walk only a few paces after lengthy instrumentation sessions would generate significant amounts of data in just a few minutes on a treadmill with Organic Motion’s markerless capture.
But the biggest issue with Organic Motion’s data was a lack of resolution. It could track head, limbs and torso quiet well. When motions were collected with one of our hybrid systems (Vicon marker and Organic Motion’s markerless) we observed good alignment of basic joint angles performed in the subject’s sagittal or frontal planes. Similar results were experienced by Becker & Russ. But we found long bone rotations to be very poor. Also because of the methodology, it was impossible to monitor finer elements of human motion such as finger motion. At the time, all markerless motion tracking systems used a form of shape or silhouette tracking.
How does markerless tracking work?
There are basically two approaches to markerless tracking, i) shape or silhouette fitting and ii) AI/Machine Learning. It is beyond the scope of this post to get into the details of how these two methods are implemented. But a quick overview will help understand the benefits and limitations of each.

Shape or silhouette fitting is basically a process of extracting a subject’s pose from outlines. Outlines obtained by removing backgrounds from multiple digital videos, taken from multiple positions, are “assembled” into a 3d object using various algorithms. Alternatively, a body model is oriented to generate a “best fit” to the multiple silhouettes. The methods and processing speed are such that realistic tracking of the body can be done in real time. But as our experience with Organic Motion showed, the rough shape of limbs does not provide for the kind of detail necessary for many biomechanical applications.
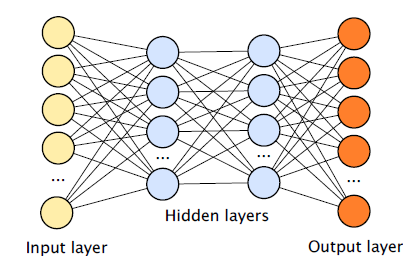
AI and Machine Learning(AI/ML) have gotten much attention in the last 5 years. AI and Convoluted Neural Networks (CNN) seem well suited for extracting finer detail from video images. The process is basically one of taking a set of inputs and mapping them to a set of outputs. But unlike a direct mapping that might occur with linear regression techniques, CNN mapping includes several hidden layers that result in non-linear transformations of input to output. As Gary Marcus of New York University points out in a critical appraisal of deep learning, the methods for achieving that mapping are complex, with results often not understood by the team creating the network. While beyond the scope of this post, for those wanting more insight into CNN and Machine Learning, see Google’s developer section for an introduction to feature identification.
Training a CNN requires that large data sets be run through the fitting routines. In the case of tracking human motion, one needs i) large numbers of images with the relevant features identified, ii) images need to include people in various poses consistent with the activities that are to be tracked, and iii) subjects and backgrounds need to be sufficiently diverse that the models can track in all environments.
Validating the trained CNN is equally daunting. Typically, a model trained on say, 90% of the dataset is used to test its ability to accurately identify the remaining 10%. Randomly picking the 90% in repeated tests allows for a very large validation test.
With images of the features taken from multiple digital videos located in different viewpoints, standard DLT techniques can be used to locate those features in 3D space.
As mentioned, the shape/silhouette approach offers fast processing and reasonable accuracy of gross motion. But its methods are limited in terms of the resolution that can be achieved.
AI/ML on the other hand, enable extracting the position of individual features such as eyes, joint centers and condyles. But the processing of video files is time consuming and not yet real time requiring several minutes to process videos of short duration. The computational requirements are also more expensive involving high end graphics cards and parallel processing on the GPU.
The Future
Our first experience with markerless motion tracking used shape/silhouette technology. However, our current belief is that AI and CNN are especially suited to tracking human motion and are, in fact, the future of motion tracking. Its primary shortfall is the time it takes to process video data, and that will be addressed as computing power and programming techniques evolve.
With AI/ML many of the traditional biomechanical analyses remain in place. For example, rigid body analyses where 3 non-colinear markers are used to track the orientation of a body segment find parallels with markerless tracking. Feature identification that includes a proximal joint center, lateral condyle and distal joint center could be right out of traditional biomechanical marker sets.
The high resolution of MI/ML also enables monitoring of such things as how a ball is held during a pitching activity.
AI/ML approaches are being commercialized by several companies including Theia, KinaTrax, Intel 3Dat, and SwRI. While we are actively evaluating all, Theia and KinaTrax have already demonstrated acceptance in their respective markets.
Thus far we have created tight integrations with Theia and KinaTrax. It is important from an “ease of use” perspective that the steps of recording video, processing video, applying AI modeling, and generating the appropriate analytical output progress without intervention after clicking the record button. The MotionMonitor’s existing structure is being used to collect digital video synchronously with standard laboratory peripherals such as forceplates and EMG. This greatly simplifies and expands the useability of Theia and Kinatrax markerless tracking.
In addition, The MotionMonitor’s unique design supports fast special purpose application development on multiple platforms. The In Game Baseball application developed for KinaTrax shown in the following video is a good example of this capability.
As a result of the progress made thus far, we believe markerless should soon enjoy the same kind of acceptance that standard tracking systems have achieved. We’re excited by the power of markerless technologies to open new markets and applications for motion capture. These technologies partnered with The MotionMonitor’s flexible interface offer innovative solutions for research, clinical applications, sports performance & training, educational applications and more.
We’d welcome the opportunity to talk with you about your applications & experiences with markerless motion capture. Feel free to connect on social media (@motionmonitor) or send us an email at support@TheMotionMonitor.com.
-Lee